Hype, evidencia y parches


Esta semana, según reportó EMOL, la CMF habría activado un monitoreo interno vinculado a un modelo de inteligencia artificial y sus riesgos a la ciberseguridad. El modelo es Mythos, de Anthropic, una de las tres compañías que concentran hoy la llamada “frontera” de la inteligencia artificial. Su lanzamiento vino acompañado de una afirmación que recorrió el mundo: en pruebas internas, el modelo habría encontrado más de 500 vulnerabilidades de seguridad de alta gravedad en software público, algunas de ellas con décadas de antigüedad. La inquietud no es solo el hallazgo: la misma capacidad que detecta fallas puede ayudar a explotarlas antes de que llegue el parche. Es decir una potencial bomba de tiempo.
De acuerdo con reportes de prensa, reguladores de al menos cuatro países (Estados Unidos, Reino Unido, Canadá y Chile) habrían elevado el tema en sus mesas internas. En el caso chileno, según EMOL, la CMF estaría coordinando con las empresas supervisadas y con la Agencia Nacional de Ciberseguridad (ANCI).
¿Qué hacer con una noticia así? ¿Vale la pena preocuparse?
Nuestra respuesta corta: antes de reaccionar a un anuncio de inteligencia artificial, conviene pasarlo por tres filtros, los llamamos hype, evidencia y parches.
1. El hype: el titular casi nunca cuenta toda la historia
Los anuncios de capacidad de modelos de inteligencia artificial están diseñados para sorprender, de la misma forma que cada modelo de teléfono parece que crea una nueva era (aunque sea casi igual al anterior). Una cifra alta, un superlativo, un titular que promete cambio de época. El problema es que esas cifras dependen casi por completo del protocolo con el que se midieron, y pequeños cambios en la prueba generan diferencias de orden de magnitud.
Un ejemplo concreto, anterior a Mythos: un estudio académico de 2024 (Fang y coautores, Universidad de Illinois) midió qué tan bien un agente basado en un modelo de frontera podía explotar vulnerabilidades de seguridad conocidas. Cuando al agente se le entregaba el identificador del problema (el llamado CVE), lograba explotar exitosamente alrededor del 87% de los casos. Cuando tenía que descubrir el problema por sí solo, sin esa pista, la tasa caía aproximadamente al 7%.
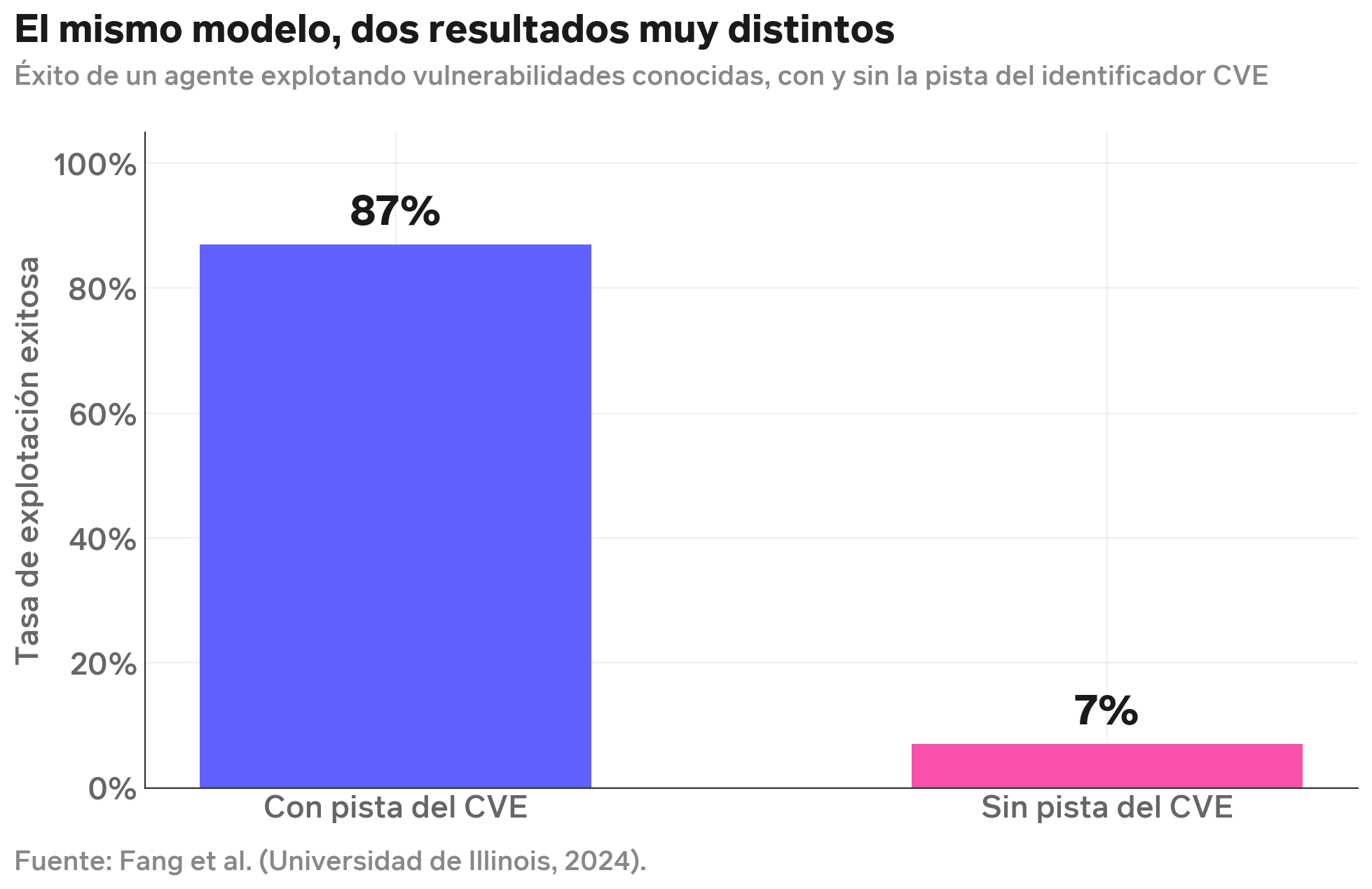
El mismo modelo, la misma infraestructura, el mismo día. Una variable de protocolo cambia la cifra por un factor de más de diez. Ese dato, bien entendido, explica buena parte del ruido actual. Cuando una empresa anuncia un resultado espectacular, la pregunta útil es ¿bajo qué condiciones?
La conclusión es que la capacidad existe, es real, y avanza rápido. Pero es irregular. Destaca en unas cosas y falla en otras, y la forma de la irregularidad importa más que la cifra agregada.
2. La evidencia: cuándo sí prestar atención
Si el primer filtro ayuda a descartar ruido, el segundo ayuda a decidir cuándo una noticia sí merece acción. Tres señales que a nosotros nos parecen útiles.
La primera: que la fuente primaria exista y se pueda leer. En el caso de Mythos, Anthropic publicó su system card, un documento técnico de varios cientos de páginas. No reemplaza a la validación externa, pero permite ver qué dicen exactamente (y, más importante, qué no dicen) los creadores del modelo.
La segunda: que la replicación independiente sea consistente. No basta que un investigador en redes sociales diga que replicó algo. Lo que cuenta es si organizaciones con incentivos distintos (un instituto público, un regulador, un banco, un equipo académico) llegan a conclusiones parecidas. En el caso de Mythos, el Instituto de Seguridad de la Inteligencia Artificial del Reino Unido (AISI, por su sigla en inglés) publicó en abril un paper evaluando a varios modelos de frontera en escenarios de ataque de múltiples pasos. La evidencia es matizada: Mythos y otros modelos recientes muestran avances reales en tareas de hasta 32 pasos, pero siguen fallando consistentemente en rangos que simulan sistemas industriales.
La tercera: que el problema se discuta en términos específicos, no épicos. Cuando una noticia se describe como “revolucionaria” o “aterradora” sin precisar qué tarea, qué modelo de amenaza y qué condiciones de prueba, la probabilidad de que sea hype es alta. Cuando la noticia viene con métricas, modelo de amenaza explícito y mención de limitaciones, la probabilidad de que sea sustantiva sube.
3. Los parches: la variable que casi nadie cuenta
Supongamos que pasamos los dos filtros anteriores. Asumamos que Mythos, u otro modelo, efectivamente puede encontrar vulnerabilidades de software a un ritmo sin precedentes. ¿Qué sigue?
Aquí aparece la tercera pregunta, la menos discutida en la prensa y, para nosotros, la más importante. Una nota reciente del estratega de mercados Michael Cembalest en J.P. Morgan lo planteó con claridad: la variable decisiva del riesgo no es la velocidad de descubrimiento de vulnerabilidades. Es la velocidad de parcheo.
Descubrir una falla es un acto técnico. Parcharla es un acto organizacional, y las organizaciones del mundo real se mueven a velocidades muy distintas según qué tipo de infraestructura operan.
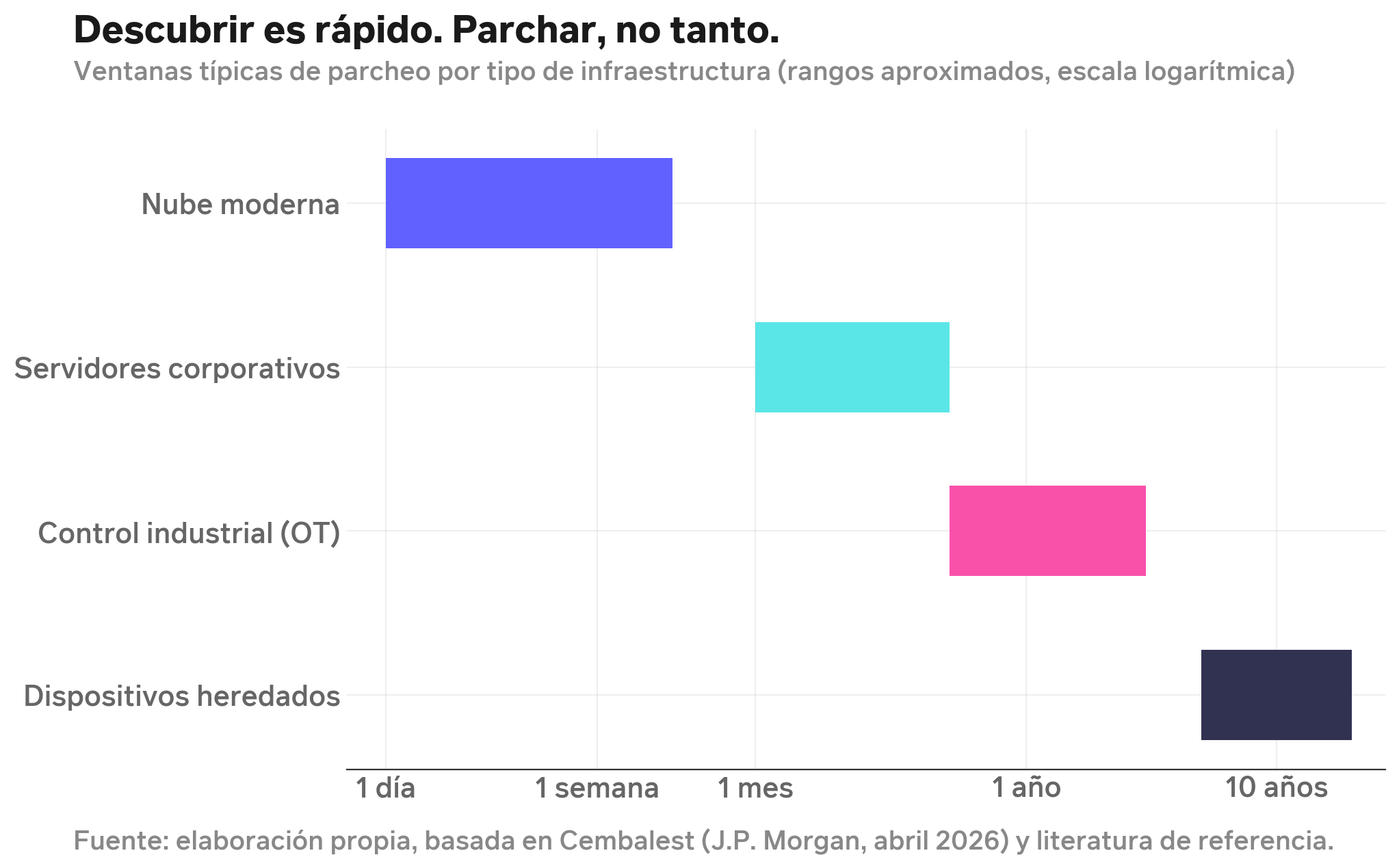
Un servicio en la nube puede aplicar un parche en días, a veces en horas. Un sistema corporativo tradicional, instalado en servidores propios y con sistemas antiguos, tarda semanas o meses, porque cada actualización requiere pruebas, ventanas de mantención y coordinación con áreas de negocio. Un sistema de control industrial (una planta eléctrica, una refinería, una red de distribución de agua) opera en ciclos de meses o años, porque detener la operación tiene costo, porque los proveedores a veces dejaron de existir, o porque el software está acoplado a hardware específico que ya no se fabrica. Y existe una cola larga de sistemas antiguos incrustados en dispositivos físicos que no se parchan nunca.
Esto no es un tecnicismo. Es la razón por la que un anuncio de inteligencia artificial capaz de descubrir vulnerabilidades “por sí sola” no se traduce automáticamente en un riesgo equivalente para todos los sectores. Los bancos, la energía, la salud y la industria no viven en la misma curva de parcheo que una aplicación web moderna. Y ese desfase, no la capacidad del modelo, es donde se concentra buena parte del riesgo real.
Tres preguntas, un método
Volviendo a la noticia del principio: según la prensa, la CMF y otros reguladores estarían mirando el tema. Es razonable que lo hagan. No porque una cifra de 500 vulnerabilidades, por sí sola, defina el riesgo. Sino porque cuando reacciones institucionales reportadas en varios países apuntan en la misma dirección, vale la pena al menos preguntarse qué hay detrás.
La pregunta útil nunca es si la inteligencia artificial cambiará las cosas. Cambiará cosas. La pregunta útil es cuán rápido, con cuánta evidencia, y cuánto tarda el mundo real en adaptarse.


